Cientistas da Alexa da Amazon demonstram que um AI maior nem sempre é melhor
Cientistas da Alexa da Amazon mostram que tamanho não importa em IA
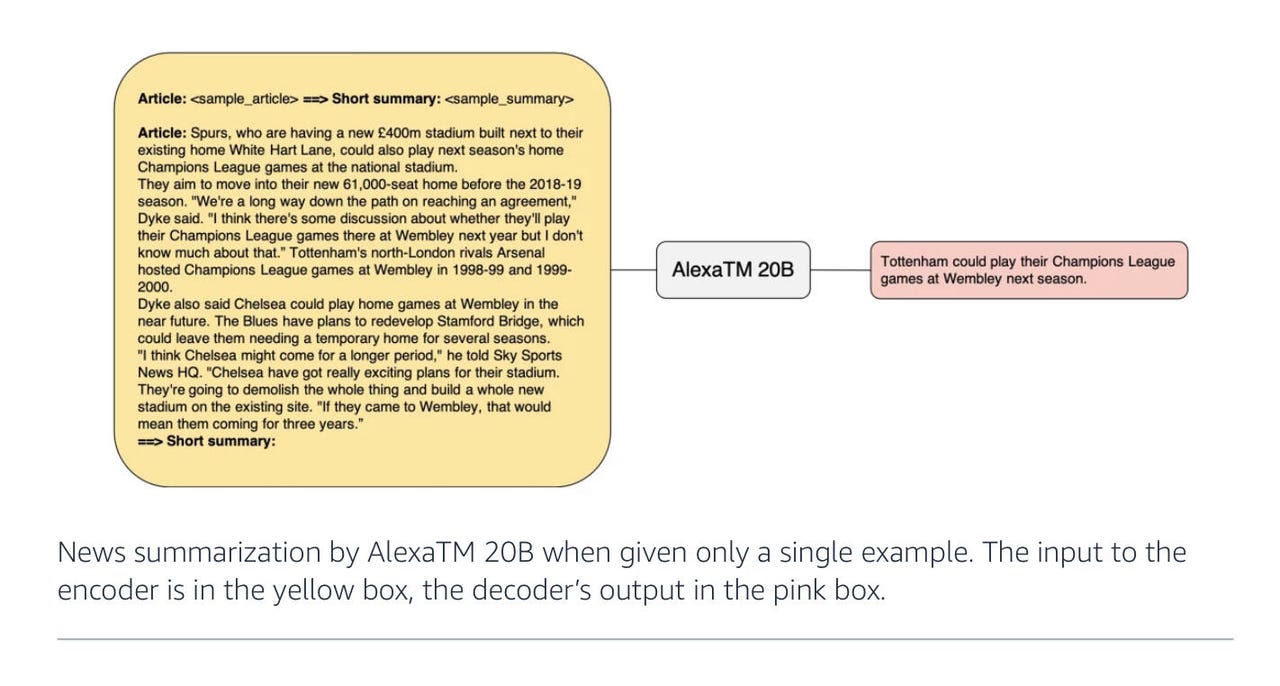
Uma tarefa simples, reduzir todas as palavras de um artigo para uma sequência compacta de palavras que explique o ponto central do artigo, está entre as tarefas de referência em aprendizado profundo. É aqui que os cientistas de IA da Amazon Alexa afirmam que podem superar os esforços de programas de computador muito maiores da DeepMind, Google, Meta, OpenAI e outros. O trabalho tem implicações para o uso de energia e eficiência da pegada de carbono.
Atualmente, duas linhas de pesquisa dominam fortemente a aprendizagem de máquina: tornar os programas mais gerais em sua abordagem (para lidar com qualquer tarefa potencial) e torná-los maiores.
As maiores redes neurais, medidas por seus parâmetros ou “pesos”, estão chegando a mais de meio trilhão de pesos. Modelos como o Modelo de Linguagem do Google Pathways, ou PaLM, e o NLG 530B da Nvidia e Microsoft Megatron-Turing estão entre os maiores, com 540 bilhões e 530 bilhões de parâmetros, respectivamente. Em geral, quanto mais parâmetros um programa tiver, maior será a quantidade de energia de computação consumida para treinar e também para executar para fazer previsões, o que é chamado de inferência.
Inteligência Artificial
- 7 dicas avançadas de escrita de prompts do ChatGPT que você precisa saber
- Os 10 melhores plugins do ChatGPT de 2023 (e como aproveitá-los ao máximo)
- Eu testei muitas ferramentas de IA para o trabalho. Estas são as minhas 5 favoritas até agora
- Humano ou robô? Este jogo de teste de Turing coloca suas habilidades de detecção de IA em teste
Os conhecedores de IA insistem que o caminho definitivamente é aumentar o número de parâmetros, em direção a um trilhão de parâmetros e além, em um futuro não tão distante. A figura de 100 trilhões é um tipo de meta mágica porque acredita-se ser o número de sinapses em um cérebro humano, servindo como um ponto de referência.
Também: Nvidia esclarece alegação de escala Megatron-Turing
- O verdadeiro objetivo da IA pode não ser mais a inteligência
- A ilusão da persona Você realmente existe nas redes sociais?
- O Metaverso é um dilema dos direitos humanos
Ao mesmo tempo, há um fervor em fazer redes neurais profundas que possam ser o mais gerais possível. Durante grande parte da história do aprendizado de máquina nos últimos 40 anos, os programas eram especializados em tarefas como reconhecimento de imagem ou reconhecimento de fala. Isso mudou nos últimos anos, com mais e mais programas se oferecendo para serem generalistas, como o Perceiver AR do DeepMind e outro programa do DeepMind, o Gato, referido como “um agente generalista” capaz de resolver várias tarefas.
A tendência de generalização tem sido reforçada pelas observações dos pioneiros da aprendizagem de máquina, como Richard Sutton, que afirmou que “historicamente, modelos genéricos que são melhores em aproveitar a computação também tenderam a ultrapassar abordagens especializadas em domínio eventualmente”.
Também: O ‘Gato’ da DeepMind é medíocre, então por que eles o construíram?
E ainda assim, há resultados de aprendizado profundo que às vezes seguem na direção oposta: contra gigantes e gerais para economia e um tanto focados, se não especializados.
Em contraste com esses mega-esforços, pesquisadores da Amazon revelaram na semana passada um programa de rede neural com apenas 20 bilhões de parâmetros que supera alguns dos modelos maiores e mais gerais em algumas tarefas de referência importantes de aprendizado profundo, como resumir um artigo.
No artigo “AlexaTM 20B: Aprendizado de Poucas Amostras Usando um Modelo Seq2Seq Multilíngue em Escala”, publicado na semana passada no arXiv, o autor Saleh Soltan e seus colegas da Amazon Alexa AI mostram que 20 bilhões de parâmetros são suficientes para superar modelos maiores como o PaLM em certas tarefas, como resumir um artigo em algumas frases.
Além do artigo, Soltan escreveu um post no blog sobre o assunto.
O trabalho da Amazon faz parte de uma tendência ampla na literatura recente de encontrar alternativas para aumentar o tamanho. Um artigo lançado na semana passada pela Meta (donos do Facebook e Instagram) intitulado “Aprendizado de Poucas Amostras com Modelos de Linguagem Auxiliados por Recuperação” é um bom exemplo. Ele descreve um modelo de linguagem chamado Atlas que possui apenas 11 bilhões de parâmetros e é treinado usando apenas 64 pontos de dados de exemplo.
Assim como o AlexaTM 20B, o programa Atlas supera o PaLM com uma margem significativa, escrevem os autores, mesmo com apenas 64 exemplos. A chave do Atlas é combinar o modelo de linguagem pré-treinado com a capacidade de recuperar informações de fontes online, como a Wikipedia, como se estivesse ligando para um amigo para obter a resposta.
Também: O Perceiver AR do DeepMind: um passo em direção à maior eficiência da IA
No caso do AlexaTM 20B, os autores da Amazon usam três ajustes para alcançar suas pontuações.
Diagrama do AlexaTM 20B da Amazon 2022
O primeiro ajuste interessante é voltar ao básico e restaurar algo retirado dos recentes modelos de linguagem gigantes. A base do AlexaTM 20B é a mesma do PaLM, GPT-3 e outros, um codificador-decodificador Transformer – a abordagem pioneira em 2017 pelos cientistas do Google Ashish Vaswani e colegas.
O Transformer usa unidades chamadas “autoatenção” para determinar uma pontuação de probabilidade para como cada palavra pode ser encontrada no contexto de outras palavras. Essa pontuação é então usada para preencher lacunas ao prever palavras e formar blocos de texto significativos.
No caso do AlexaTM 20B, Soltan e colegas fazem uma saída crítica do PaLM, GPT-3 e outros descendentes gigantes do Transformer original. Esses modelos mais recentes dispensaram metade do Transformer, o que é chamado de codificador (a parte que mapeia os dados de entrada em estados ocultos para então serem decodificados em uma resposta). Em vez disso, o PaLM e o GPT-3 mesclam a entrada com o decodificador, formando um programa simplificado que é um modelo “apenas-decodificador”.
A equipe do Alexa coloca o codificador de volta no programa. Eles afirmam que ter ambos os elementos ajuda a melhorar a precisão no que é chamado de “remoção de ruído”, ou seja, reconstruir uma frase original em que algumas palavras tenham sido omitidas.
No modelo “apenas-decodificador”, a probabilidade condicional do texto previsto ocorre apenas em uma direção: cada próxima resposta é baseada apenas no que veio antes. Na versão completa codificador-decodificador, por outro lado, o modelo faz uma avaliação das probabilidades em ambas as direções: o que veio antes de uma determinada palavra e o que segue. Isso é mais útil em tarefas em que não apenas se gera o próximo elemento de uma frase, mas também se realiza coisas como comparação palavra por palavra, como em tarefas de tradução de um idioma para outro.
Modelos apenas-decodificador do AlexaTM 20B da Amazon 2022
Também: A grandiosa obra de tradução multilíngue da Meta ainda enfrenta dificuldades com o grego, o armênio e o oromo
Conforme escrevem, “o AlexaTM 20B alcança um novo estado da arte de 82,63% na configuração de zero-shot no modo de remoção de ruído. A principal razão pela qual o modo de remoção de ruído funciona melhor para essa tarefa é que, nesse modo, a entrada é repetida no codificador e no decodificador, permitindo que o modelo utilize completamente ambos para encontrar a melhor resposta.”
A segunda coisa que os autores adicionam é treinar o modelo com o que é chamado de “modelagem de linguagem causal”. CLM, abreviação de Causal Language Modeling, é a tarefa usada no GPT-3 e em outros Transformers apenas-decodificadores. Ele representa especificamente cada palavra como dependente apenas das palavras que vieram antes – uma dependência sequencial unidirecional que é treinada para gerar frases com base em um prompt inicial.
Os autores misturam a tarefa de remoção de ruído com a tarefa causal no treinamento do AlexaTM 20B, com a remoção de ruído ocupando 80% da atividade de treinamento e a modelagem causal os 20% restantes.
A virtude de adicionar a modelagem causal é que, assim como o GPT-3, ela ajuda no que é chamado de “aprendizagem em contexto”. A aprendizagem em contexto é um conceito amplo que abrange modelos capazes de realizar aprendizagem zero ou de poucas amostras. Isso significa que o programa não possui conhecimento específico de domínio; você apenas fornece um exemplo de prompt, e o programa faz uma previsão de acordo com o tipo de pergunta feita.
Devido a esse regime de treinamento híbrido, o AlexTM 20B não apenas se sai bem em reconstruir frases – a tarefa de remoção de ruído -, mas também é “o primeiro modelo seq2seq multilíngue capaz de aprendizagem em contexto”, escrevem os autores. É um programa híbrido, em outras palavras.
O terceiro ajuste interessante feito por Soltan e colegas é aumentar enormemente a quantidade de pontos de dados inseridos no programa durante o treinamento. Eles inserem um trilhão de “tokens”, peças individuais de dados, durante o treinamento; isso é mais que três vezes a quantidade que o GPT-3 recebe. Os conjuntos de dados de treinamento neste caso consistem em entradas da Wikipedia e também no que é chamado mC4, um conjunto de dados para treinar Transformers introduzido no ano passado por Linting Xue e colegas do Google. Ele é baseado em texto em linguagem natural em 101 idiomas provenientes de fontes de dados da web Common Crawl.
Também: Sentiente? Google LaMDA parece um chatbot típico
O uso de uma quantidade muito grande de dados de treinamento de entrada é um dos elementos-chave do trabalho da Alexa. Soltan e sua equipe decidiram seguir por esse caminho, escrevem eles, com base em uma observação feita por Jordan Hoffman e colegas da OpenAI, publicada em um artigo em março passado, “Treinamento de modelos de linguagem grandes de forma otimizada para computação”.
Nesse artigo, Hoffman e seus colegas concluem que “os modelos de linguagem grandes atuais estão significativamente subtreinados, consequência do foco recente em dimensionar modelos de linguagem enquanto mantém a quantidade de dados de treinamento constante”. Ao utilizar uma ampla variedade de modelos de linguagem de diferentes tamanhos e testá-los com quantidades variadas de tokens de entrada, os autores concluíram que “para um treinamento ótimo em termos de computação, o tamanho do modelo e o número de tokens de treinamento devem ser dimensionados igualmente”.
Portanto, a AlexaTM 20B não é apenas parcimoniosa – ela visa provar que menos parâmetros podem ser equilibrados com mais dados de treinamento para obter um desempenho convincente.
A ENBLE recomenda
Qual Amazon Echo comprar? Como escolher o melhor dispositivo Alexa para suas necessidades
A Amazon agora possui um exército inteiro de dispositivos Echo. Alguns ouvem você. Alguns também te observam. Qual você deve escolher? Nós te ajudamos a decidir.
Curiosamente, os autores também se esforçam para moldar a maioria das entradas como texto falado natural, deixando de lado a capitalização e pontuação, o que é importante em um ambiente Alexa. “Incluímos mais texto falado do que escrito para atender às nossas necessidades internas”, escrevem eles.
Algumas das tecnologias da equipe de IA da Alexa são usadas em produtos Alexa, embora a Amazon tenha informado à ENBLE em um e-mail que o grupo “também realiza pesquisas prospectivas”. O modelo AlexaTM 20B, segundo a Amazon, “é principalmente um projeto de pesquisa nesta fase”.
A Amazon acrescentou: “É possível que este modelo seja implantado em produção no futuro, mas apenas a versão modificada com salvaguardas será usada para desenvolver recursos e produtos Alexa”.
Também: O trabalho massivo de tradução de idiomas do Google identifica onde ele comete erros
Os autores treinaram o modelo AlexaTM 20B “por 120 dias em 128 GPUs Nvidia A100 para um total de 500 mil atualizações com o tamanho total do lote de 2 milhões de tokens (total de 1 trilhão de atualizações de tokens)”, escrevem eles.
Isso pode parecer muito, mas é menos do que o PaLM, que foi treinado pelo Google em dois de seus Pods TPU de quarta geração, compostos por 3.072 chips TPU em cada Pod, que estão conectados a 768 computadores hospedeiros.
Conforme observado pelos autores do Google Aakanksha Chowdhery e sua equipe em abril, isso foi “a maior configuração de TPU descrita até o momento”.
Os resultados são detalhados em resultados de testes específicos. Soltan e sua equipe enfatizam especialmente o sucesso em tarefas específicas em oposição a todas as tarefas concebíveis. Por exemplo, Soltan e sua equipe observam que “a AlexaTM 20B tem um desempenho melhor ou igual ao maior modelo decodificador denso até o momento (ou seja, PaLM 540B) em sumarização, tanto em configurações de 1-shot quanto de ajuste fino”. Isso é especialmente verdadeiro em uma tarefa de resumir parágrafos conhecida como MLSum; em alemão, espanhol e francês, a AlexaTM 20B superou facilmente o PaLM.
O teste de referência MLSum, introduzido em 2020 pelo Centro Nacional de Pesquisa Científica da França, compreende 1,5 milhão de artigos de jornais. A tarefa é para um modelo de linguagem produzir algumas frases de texto que expressem a ideia apresentada no artigo inteiro. Isso requer uma grande redução, obviamente, de centenas de palavras para talvez algumas dezenas.
Amazon
- Como transformar seu antigo tablet Fire em um Echo Show
- Troque seus dispositivos antigos por cartões-presente da Amazon. Veja como
- Os melhores tablets da Amazon: Brinque com o Fire
- Avaliação do Amazon Kindle Scribe: 7 meses depois, está quase perfeito
Em um quarto teste, XSum, realizado em inglês, o modelo AlexaTM 20B ficou em segundo lugar e superou uma versão do PaLM que era maior que o AlexaTM 20B, mas menor do que a versão de 540 bilhões de parâmetros do PaLM.
Embora seja excelente em sumarização, o AlexTM 20B falha em algumas outras tarefas. Por exemplo, testado em conjuntos de dados de “raciocínio” (como o MultiArith) e tarefas de “cadeia de pensamento” (que são problemas de aritmética muito simples escritos em linguagem natural), o programa fica muito atrás do que é alcançado pelos modelos muito maiores como o GPT-3.
Também: O futuro da IA é uma história de software, diz CEO da Graphcore
Escreve Soltan e equipe, “AlexaTM 20B tem um desempenho ligeiramente melhor do que modelos de tamanho semelhante, no entanto, não observamos o ganho que modelos muito maiores como GPT3 175B mostram a partir de prompts especiais,” ou seja, pistas dadas ao programa sobre o próximo passo em um problema.
“Os resultados indicam que aumentar os parâmetros do modelo é crucial para um bom desempenho em tarefas de ‘raciocínio’, como já foi demonstrado anteriormente em arquiteturas apenas de decodificador usando modelos Instruct-GPT3.”
Ao se concentrar nas tarefas bem-sucedidas, como sumarização, a principal conclusão a que Soltan e equipe chegam é que sua abordagem mista para treinar o programa – usando tanto objetivos de desruído quanto modelagem de linguagem causal – é a chave para tornar as coisas mais eficientes.
“Isso sugere que o pré-treinamento misto, e não necessariamente treinamento adicional multitarefa, é a chave para treinar Modelos de Linguagem em Grande Escala (LLM) baseados em seq2seq fortes”, eles escrevem.
Para voltar à pergunta original sobre o tamanho, como foi observado em muitos contextos, o consumo de energia de programas de IA cada vez maiores é uma preocupação ética dentro das práticas de IA. Os autores apresentam um forte argumento para a relevância de sua abordagem mais eficiente.
Também: Ética da IA: Benefícios e riscos da inteligência artificial
Porque o AlexaTM 20B “é muito menor em tamanho do que modelos como GPT3 175B, mas alcança desempenho semelhante ou melhor em diferentes tarefas”, eles escrevem, “o impacto ambiental contínuo de usar o AlexaTM 20B para inferência é muito menor do que o de modelos maiores (aproximadamente 8,7 vezes menor)”.
Eles acrescentam: “Portanto, ao longo do tempo, o AlexaTM 20B também tem uma pegada de carbono menor”.
Os autores oferecem uma tabela de estatísticas mostrando a pegada de carbono relativa, e há uma grande diferença nos números.
Este é um gráfico de comparação de pegada de carbono do Amazon 2022 AlexTM 20B.
Essa tabela de pegadas de carbono é talvez o aspecto mais interessante de tudo isso. Parece que mais pesquisas em aprendizado profundo buscarão pontuações para avaliações ambientais, a fim de mostrar como uma abordagem pode ser energeticamente eficiente. Isso está de acordo com o foco crescente do mundo em fatores “ESG”, ou seja, ambientais, sociais e de governança, em todas as coisas.
Isso pode significar que ser ecologicamente consciente se tornou, de alguma forma, parte do objetivo da pesquisa em IA mainstream.
Também: IA em sessenta segundos