Como o Google e a UCLA estão incentivando a IA a escolher a próxima ação para uma resposta melhor
Google e UCLA incentivam IA a escolher a próxima ação para melhor resposta
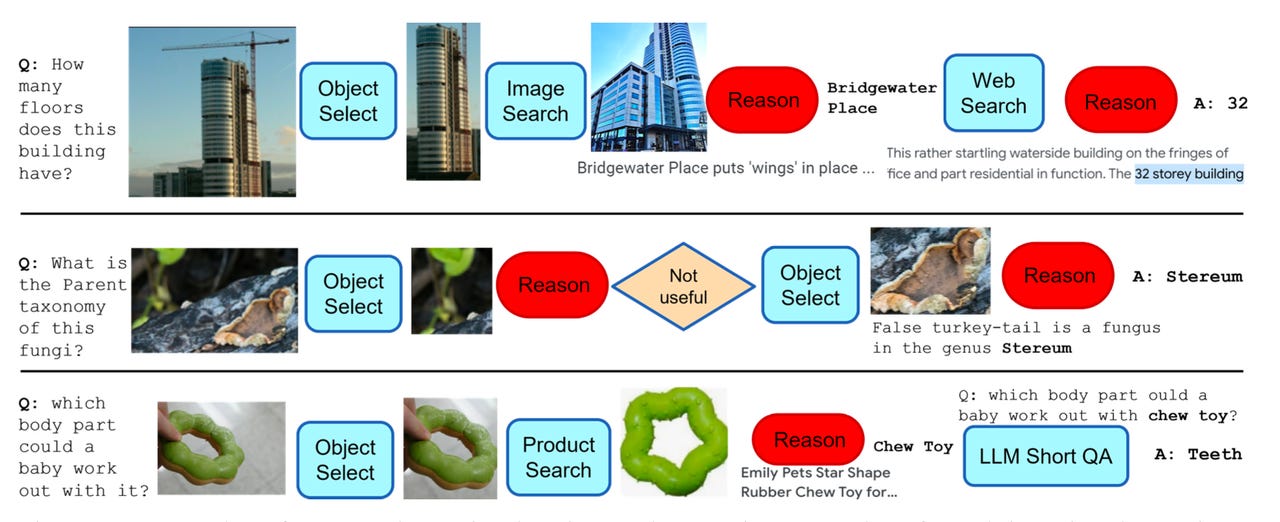
O programa AVIS do Google pode selecionar dinamicamente uma série de etapas a serem realizadas, como identificar um objeto em uma imagem e buscar informações sobre esse objeto.
Os programas de inteligência artificial impressionaram o público com a forma como produzem uma resposta, independentemente da consulta. No entanto, a qualidade da resposta muitas vezes deixa a desejar, pois programas como o ChatGPT simplesmente respondem à entrada de texto, sem nenhum conhecimento específico no assunto, e podem produzir falsidades.
Um recente projeto de pesquisa da Universidade da Califórnia e do Google permite que grandes modelos de linguagem, como o ChatGPT, selecionem uma ferramenta específica – seja uma busca na web ou reconhecimento óptico de caracteres – que pode buscar uma resposta em várias etapas a partir de uma fonte alternativa.
Também: O ChatGPT mente sobre resultados científicos, dizem pesquisadores, e precisa de alternativas de código aberto
O resultado é uma forma primitiva de “planejamento” e “raciocínio”, uma maneira de um programa determinar a cada momento como uma pergunta deve ser abordada e, uma vez respondida, se a solução foi satisfatória.
- CEO da indústria farmacêutica Não pare a pesquisa em IA, nosso trab...
- Estes novos aspiradores Roborock de gama média podem fazer você rep...
- Cerebras e Abu Dhabi constroem o modelo de IA em árabe mais poderos...
O esforço, chamado AVIS (para “Autonomous Visual Information Seeking with Large Language Models”) por Ziniu Hu e colegas da Universidade da Califórnia em Los Angeles, e autores colaboradores do Google Research, está publicado no servidor de pré-impressão arXiv.
AVIS é construído no Pathways Language Model, ou PaLM, do Google, um grande modelo de linguagem que gerou várias versões adaptadas a uma variedade de abordagens e experimentos em IA generativa.
AVIS está na tradição de pesquisas recentes que buscam transformar programas de aprendizado de máquina em “agentes” que agem de maneira mais ampla do que apenas produzir uma previsão da próxima palavra. Eles incluem BabyAGI, um “sistema de gerenciamento de tarefas com IA” introduzido este ano, e PaLM*E, introduzido este ano por pesquisadores do Google, que pode instruir um robô a seguir uma série de ações no espaço físico.
O grande avanço do programa AVIS é que, ao contrário do BabyAGI e do PaLM*E, ele não segue um curso de ação pré-determinado. Em vez disso, ele usa um algoritmo chamado “Planner” que seleciona entre uma escolha de ações no momento, à medida que cada situação surge. Essas escolhas são geradas à medida que o modelo de linguagem avalia o texto solicitado, dividindo-o em subperguntas e correlacionando essas subperguntas a um conjunto de possíveis ações.
Até mesmo a escolha de ações é uma abordagem inovadora aqui.
Também: O Google atualiza o Vector AI para permitir que as empresas treinem o GenAI com seus próprios dados
Hu e colegas fizeram uma pesquisa com 10 pessoas que tiveram que responder aos mesmos tipos de perguntas – perguntas como “Qual é o nome do inseto?” mostrado em uma imagem. Suas escolhas de ferramentas, como a Pesquisa de Imagens do Google, foram registradas.
Os autores, então, colocaram esses exemplos de escolhas humanas em um “gráfico de transição”, um modelo de como os humanos fazem escolhas de ferramentas em cada momento.
O Planner então usa o gráfico, escolhendo entre “exemplos relevantes no contexto […] que são montados a partir das decisões anteriormente tomadas pelos humanos”. É uma maneira de fazer com que o programa se baseie nas escolhas dos humanos, usando exemplos passados como mais uma entrada para o modelo de linguagem.
Também: A onda de visão múltipla da IA está chegando, e será poderosa
Para servir como uma verificação de suas escolhas, o programa AVIS possui um segundo algoritmo, um “Reasoner”, que avalia a utilidade de cada ferramenta após ser testada pelo modelo de linguagem, antes de decidir se deve fornecer uma resposta à pergunta original. Se a escolha da ferramenta não foi útil, o Reasoner envia o Planner de volta à prancheta.
O fluxo de trabalho total do AVIS consiste em elaborar perguntas, selecionar ferramentas e, em seguida, usar o Reasoner para verificar se a ferramenta produziu uma resposta satisfatória.
Hu e sua equipe testaram o AVIS em alguns testes padronizados automatizados de resposta a perguntas visuais, como o OK-VQA, introduzido em 2019 por pesquisadores da Universidade Carnegie Mellon. Nesse teste, o AVIS alcançou “uma precisão de 60,2, maior do que a maioria dos métodos existentes adaptados para esse conjunto de dados”, relatam eles. Em outras palavras, a abordagem geral aqui parece superar métodos que foram cuidadosamente adaptados para se adequar a uma tarefa específica, um exemplo da crescente generalidade da IA de aprendizado de máquina.
Também: IA Generativa lidera as 25 principais tecnologias emergentes da Gartner para 2023
Ao concluir, Hu e sua equipe observam que esperam ir além das perguntas apenas relacionadas a imagens em trabalhos futuros. “Nosso objetivo é estender nosso framework dinâmico e de tomada de decisão, alimentado por LLM, para lidar com outras tarefas de raciocínio”, eles escrevem.