A Meta revela o tradutor de fala para fala ‘Seamless
Meta reveals the speech-to-speech translator 'Seamless

Meta, proprietária do Facebook, Instagram e WhatsApp, revelou na terça-feira seu mais recente esforço em tradução automática, desta vez voltado para a tradução de fala. O programa, SeamlessM4T, supera os modelos existentes que são treinados especificamente para tradução de fala para fala entre idiomas, bem como modelos que convertem entre fala e texto em vários pares de idiomas. Assim, o SeamlessM4T é um exemplo não apenas de generalidade, mas também do que é chamado de multimodalidade – a capacidade de um programa operar em vários tipos de dados, neste caso, dados de fala e texto.
Também: Meta lançará modelo de IA comercial de código aberto para competir com OpenAI e Google
Anteriormente, a Meta focava em grandes modelos de linguagem que podem traduzir texto entre 200 idiomas diferentes. Esse foco em texto é um problema, afirmam o autor principal Loïc Barrault e colegas da Meta e da UC California em Berkeley.
“Embora modelos unimodais únicos, como o No Language Left Behind (NLLB), ampliem a cobertura de tradução de texto para texto (T2TT) para mais de 200 idiomas, os modelos unificados S2ST [fala para fala para texto] estão longe de alcançar uma abrangência ou desempenho semelhantes”, escrevem Barrault e equipe.
O artigo formal, “SeamlessM4T – Tradução Automática Multilíngue e Multimodal em Massa”, está publicado no site dedicado da Meta para o projeto geral, Comunicação Sem Emendas. Há também um site companion no GitHub.
- Estes são os últimos suportes de luz que você jamais precisará
- A nova funcionalidade do YouTube identificará músicas apenas pelo s...
- Meta planeja lançar criptografia de ponta a ponta para o Messenger ...
A fala foi deixada para trás em parte porque há menos dados de fala prontamente disponíveis no domínio público para treinar redes neurais, escrevem os autores. Mas há um ponto mais profundo: os dados de fala são fundamentalmente mais ricos como um sinal para redes neurais.
“O próprio desafio em torno de por que a fala é mais difícil de abordar do ponto de vista da tradução automática – que ela codifica mais informações e componentes expressivos – é também o motivo pelo qual ela é superior para transmitir intenção e criar laços sociais mais fortes entre os interlocutores”, escrevem eles.
O objetivo do SeamlessM4T é criar um programa que seja treinado tanto em dados de fala quanto em dados de texto ao mesmo tempo. O “M4T” significa “Tradução Automática Multilíngue e Multimodal em Massa”. A multimodalidade é uma parte explícita do programa.
Também: O mais recente modelo de IA da Meta disponibilizará conteúdo em centenas de idiomas
Esse tipo de programa é às vezes chamado de programa “end-to-end” porque ele não divide as partes que são sobre texto e as partes que são sobre fala em funções separadas, como no caso de “modelos em cascata”, em que o programa primeiro é treinado em uma coisa, como fala para texto, e depois em outra coisa, como fala para fala.
Como os autores do programa explicam, “a maioria dos sistemas S2ST [tradução de fala para fala] hoje depende fortemente de sistemas em cascata compostos por vários subsistemas que realizam a tradução progressivamente – por exemplo, do reconhecimento automático de fala (ASR) para T2TT [tradução de texto para texto] e, subsequentemente, síntese de texto para fala (TTS) em um sistema de 3 estágios”.
Em vez disso, os autores construíram um programa que combina várias partes existentes treinadas juntas. Eles incluíram “SeamlessM4T-NLLB, um modelo T2TT multilíngue em massa”, além de um programa chamado w2v-BERT 2.0, “um modelo de aprendizado de representação de fala que aproveita dados de áudio de fala não rotulados”, além de T2U, “um modelo de sequência de sequência de texto para unidade” e HiFi-GAN multilíngue, um “vocoder de unidade para sintetizar fala a partir de unidades”.
Também: ‘data2vec’ da Meta é um passo em direção a Uma Rede Neural para Dominar Todas as Coisas
Todos os quatro componentes são conectados como um conjunto de Lego em um único programa, também introduzido este ano pela Meta, chamado UnitY, que pode ser descrito como “um framework de modelagem de duas etapas que primeiro gera texto e posteriormente prevê unidades acústicas discretas”.
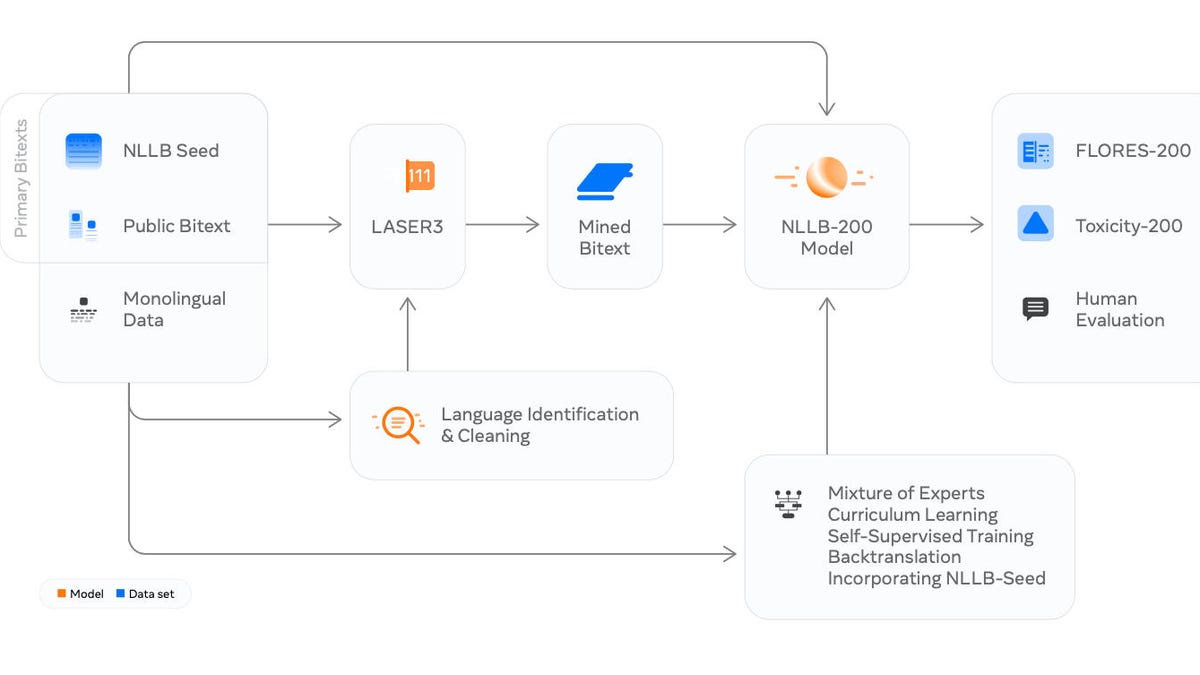
Toda a organização está visível no diagrama abaixo.
Os autores construíram um programa que combina várias partes existentes treinadas juntas, todas as quais são conectadas como um conjunto de Lego em um único programa.
O programa consegue ter um desempenho melhor do que vários outros tipos de programas em testes de reconhecimento de fala, tradução de fala e texto para fala, relatam os autores. Isso inclui superar tanto programas baseados em contaminação que também são ponta a ponta, quanto programas projetados especificamente para fala:
Nós descobrimos que o SeamlessM4T-Large, o modelo maior dos dois que lançamos, supera o estado-da-arte anterior (SOTA) do modelo S2TT ponta a ponta (AudioPaLM-2-8B- AST [Rubenstein et al., 2023]) em 4.2 pontos BLEU no Fleurs [Conneau et al., 2022] ao traduzir para o inglês (ou seja, uma melhoria de 20%). Comparado a modelos em cascata, o SeamlessM4T-Large melhora a precisão da tradução em mais de 2 pontos BLEU. Ao traduzir do inglês, o SeamlessM4T-Large melhora o SOTA anterior (XLS- R-2B-S2T [Babu et al., 2022]) em 2.8 pontos BLEU no CoVoST 2 [Wang et al., 2021c], e seu desempenho é comparável a sistemas em cascata no Fleurs. Na tarefa S2ST, o SeamlessM4T-Large supera modelos em cascata de 3 estágios fortes (ASR, T2TT e TTS) em 2.6 pontos ASR-BLEU no Fleurs. No CVSS, o SeamlessM4T-Large supera um modelo em cascata de 2 estágios (Whisper-Large-v2 + YourTTS [Casanova et al., 2022]) por uma margem significativa de 8.5 pontos ASR-BLEU (uma melhoria de 50%). Avaliações humanas preliminares dos resultados do S2TT também mostraram resultados impressionantes. Para traduções do inglês, os escores XSTS para 24 idiomas avaliados estão consistentemente acima de 4 (em 5); para direções para o inglês, vemos uma melhoria significativa em relação à linha de base do Whisper-Large-v2 para 7 dos 24 idiomas.
Além disso: Os “óculos de tradução” do Google estavam realmente na I/O 2023, bem diante de nossos olhos
O site de acompanhamento no GitHub oferece não apenas o código do programa, mas também o SONAR, uma nova tecnologia para “incorporar” dados multimodais, e o BLASAR 2.0, uma nova versão de uma métrica para avaliar automaticamente tarefas multimodais.